Google DeepMind published a new AlphaEvolve update on May 7, 2026. The interesting part is not simply that another AI coding agent exists. AlphaEvolve is a Gemini-powered system for designing and optimizing algorithms, and DeepMind now points to impact across genomics, electricity grids, quantum computing, TPUs, databases, logistics, advertising, and materials science.
For AI tool users, this is a useful signal. Coding agents are not only moving faster inside editors. They are also moving toward measurable optimization loops: propose candidates, evaluate them, keep what improves the metric, and discard the rest.
What changed in this update
DeepMind first introduced AlphaEvolve a year ago as a Gemini-powered coding agent for advanced algorithm design. This update reads like an impact map rather than a normal product note.
The official examples are concrete:
- In genomics, AlphaEvolve helped improve DeepConsensus and reduce variant detection errors by 30%.
- In grid optimization, it was applied to the AC Optimal Power Flow problem and improved a trained GNN model's feasible-solution rate from 14% to over 88%.
- In earth sciences, it helped optimize Earth AI models and improved overall natural-disaster risk prediction accuracy by 5% across 20 categories.
- In quantum computing, it suggested quantum circuits with 10x lower error than previous conventionally optimized baselines.
- In Google's infrastructure, it has been used for next-generation TPU design, cache replacement policies, Spanner compaction heuristics, and compiler optimization. DeepMind says the Spanner work reduced write amplification by 20%, while compiler-related optimizations reduced software storage footprint by nearly 9%.
Those numbers do not mean every team can reproduce the same gains next week. They do show where the category is going. When a coding task has a clear objective and a reliable evaluator, an AI agent can search across implementations instead of merely writing a plausible first draft.

This is not the same job as Cursor or Copilot
Cursor, GitHub Copilot, and AlphaEvolve sit in different parts of the AI coding stack.
Cursor is strongest when you want project-aware editing, multi-file changes, and ongoing conversation with a codebase. GitHub Copilot is strongest when you want low-friction suggestions inside an existing IDE and GitHub workflow. AlphaEvolve is closer to an algorithm discovery and optimization system. It proposes candidate programs and relies on automated evaluation to decide what is actually better.
That distinction matters. AlphaEvolve should not be read as a Gemini-flavored Copilot. It is a sign of a higher-level coding-agent pattern: when the target metric is explicit, such as lower latency, better accuracy, less storage, fewer errors, or shorter routes, the agent can explore a solution space.
Most teams do not need AlphaEvolve itself to learn from the pattern. They can make everyday AI coding work more reliable by turning vague requests into verifiable tasks. Instead of asking an assistant to "optimize this," give it the benchmark, constraints, rollback path, and acceptance criteria.
The evaluator is the real lesson
The most important part of the AlphaEvolve story is not the chat interface. It is the evaluator.
The system can only improve algorithms when there is a way to measure improvement. Did the error rate drop? Did the feasible-solution rate improve? Did write amplification go down? Did the route get shorter? Those questions create feedback.
Many teams using AI coding tools have the generator but not the evaluator. They can produce code quickly, but they do not have stable tests, benchmarks, review checklists, or production metrics. Without that, it is hard to know whether the new code is actually better.
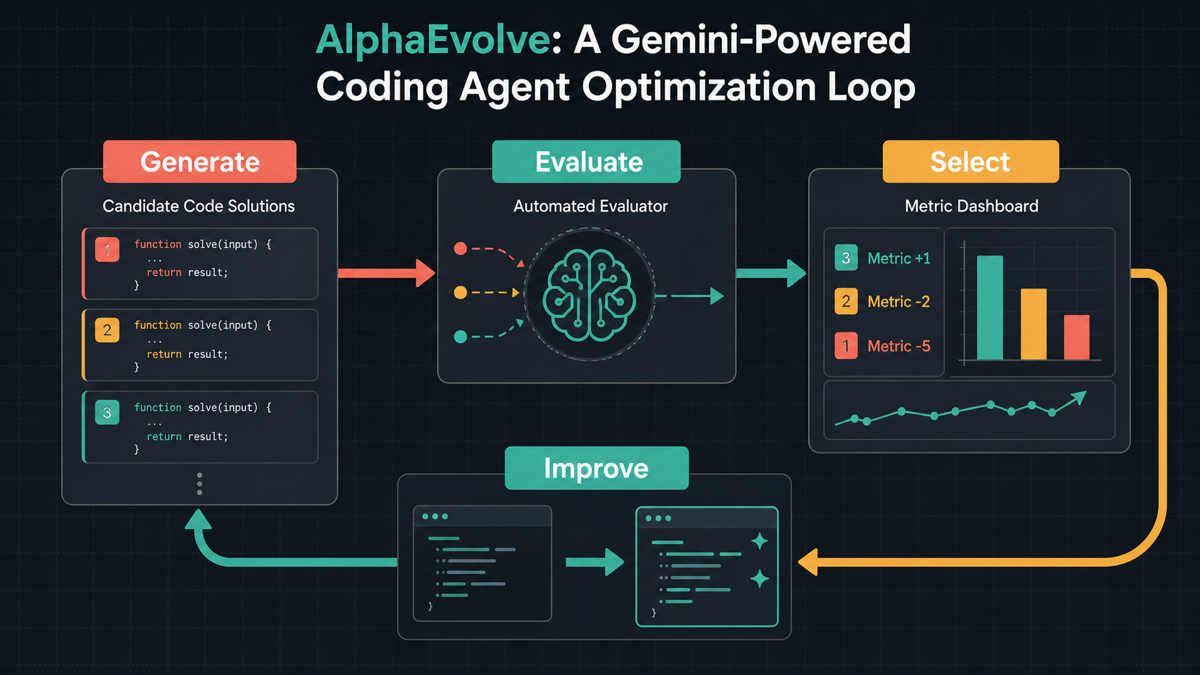
A smaller version of the AlphaEvolve workflow looks like this:
- Define the optimization target: speed, cost, accuracy, reliability, or maintainability.
- Prepare the evaluator: tests, benchmarks, static checks, or business metrics.
- Ask the AI to produce multiple candidate approaches, not just one patch.
- Use local verification and human review to keep the smallest safe improvement.
This is slower than accepting the first answer, but it produces code that is easier to trust.
What it means for tool selection
This update does not make Cursor or Copilot obsolete. It makes the split clearer.
Use Cursor when the work lives inside a repository and needs project context. Use GitHub Copilot when you want fast completion and familiar editor integration. Watch Gemini and DeepMind's tooling when the task is closer to algorithm search, model work, or Google Cloud infrastructure.
The buying criteria should also change. Instead of only asking which assistant gives the most impressive answer, ask:
- Can it work against a clear metric?
- Can it generate and compare multiple candidates?
- Can it explain why one candidate is better?
- Can it keep changes inside a reviewable scope?
- Can it fit into tests, benchmarks, CI, and code review?
AlphaEvolve points toward a future where the best AI coding tools are not just better at conversation. They are better at constrained optimization.
How to try the lesson now
Individual developers can start small. Before asking an AI assistant to change code, write down the command that proves the change works. That might be npm test, npm run build, a benchmark script, or a small regression test.
Teams can go one step further. Pick a low-risk optimization task with a clear metric. Ask the AI for multiple approaches. Run the evaluator. Review the diff. Keep the smallest improvement that passes.
The main takeaway from AlphaEvolve is not that every team needs a specialized algorithm-discovery agent today. It is that AI coding work becomes much more useful when the loop is measurable: the AI proposes, the evaluator filters, and humans decide what is worth shipping.
Reference:
- Google DeepMind: AlphaEvolve: How our Gemini-powered coding agent is scaling impact across fields https://deepmind.google/blog/alphaevolve-impact/





