On May 8, 2026, arXiv listed a paper worth watching: “LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling.” The paper introduces AutoTTS, a framework that turns test-time scaling strategy design into an environment where an agent can discover better strategies automatically.
Test-time scaling means allocating more computation during inference so a model can improve the result through additional candidates, steps, checks, or verifiers. The difficulty is that many strategies are still hand-crafted. Researchers decide when to branch, when to continue, when to probe, when to prune, and when to stop. AutoTTS asks whether those control policies can be searched instead.
What Problem the Paper Tackles
The paper’s starting point is that current test-time scaling methods leave much of the compute-allocation space unexplored because strategies are often designed manually. AutoTTS changes what researchers design. Instead of writing each heuristic directly, they construct an environment where strategies can be discovered.
The concrete example is width-depth test-time scaling. Width means branching into multiple candidate reasoning trajectories. Depth means continuing a promising trajectory further. A controller decides whether to branch, continue, probe, prune, or stop. To keep the search affordable, the paper uses pre-collected reasoning trajectories and probe signals, so candidate controllers can be evaluated cheaply without repeatedly calling the LLM.
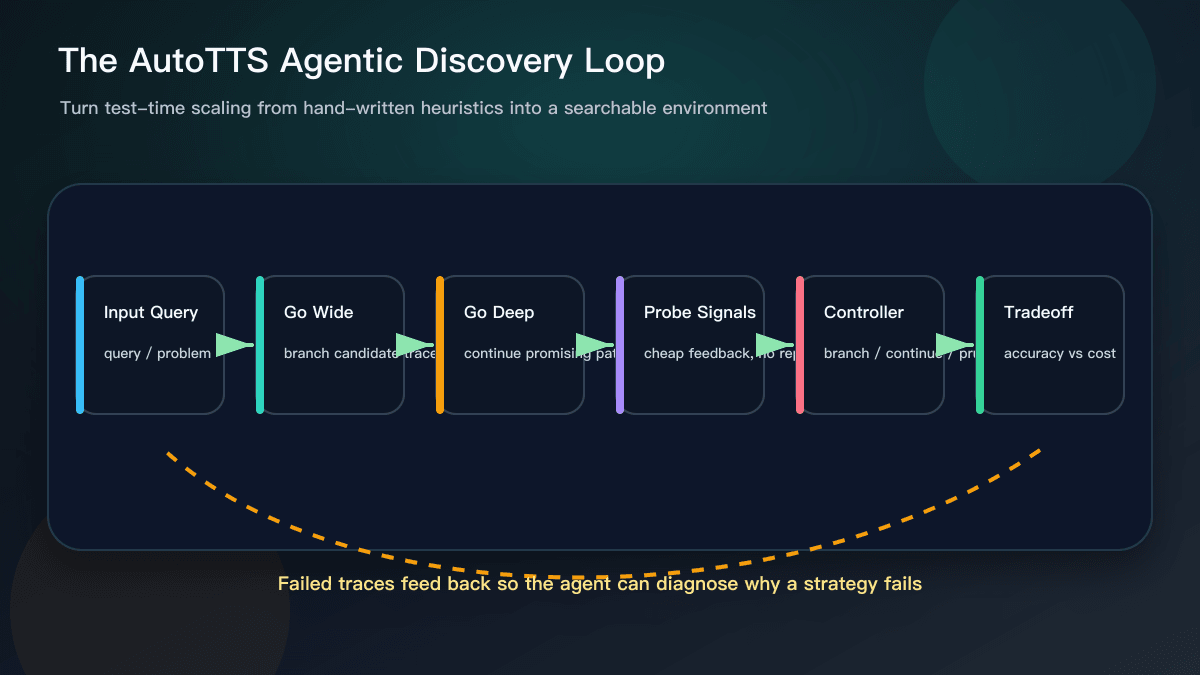
Why Tool Users Should Care
This sounds like research, but it is close to everyday AI tool use. When developers use Cursor, GitHub Copilot, or another coding assistant, they are often doing an informal version of test-time scaling. They ask for multiple solutions, request tests, inspect failure logs, rerun validation, and stop bad directions. The difference is that most teams do this through prompts rather than a systematic controller.
AutoTTS points to a useful idea: better AI workflows may come not only from stronger base models, but also from better budget allocation. When should the model generate more candidates? When should it go deeper on one solution? When should the system prune an option quickly? When can a cheap signal decide whether a path is worth continuing? Those choices affect quality, cost, and latency.
The paper reports that the discovered strategies improved the accuracy-cost tradeoff on mathematical reasoning benchmarks and generalized to held-out benchmarks and model scales. It also states that the discovery process cost $39.9 and took 160 minutes. Those numbers should not be copied directly into business planning, but they do show a direction: reasoning strategy itself can become an optimization target.
What This Means for AI Coding
AI coding is a strong fit for this pattern because software work usually has evaluators. Tests can pass or fail. Types compile or do not. Performance benchmarks regress or improve. Lint can catch style issues. A diff can be too large for review. When feedback is cheap and frequent, an agent can compare candidate approaches instead of relying on the first plausible answer.
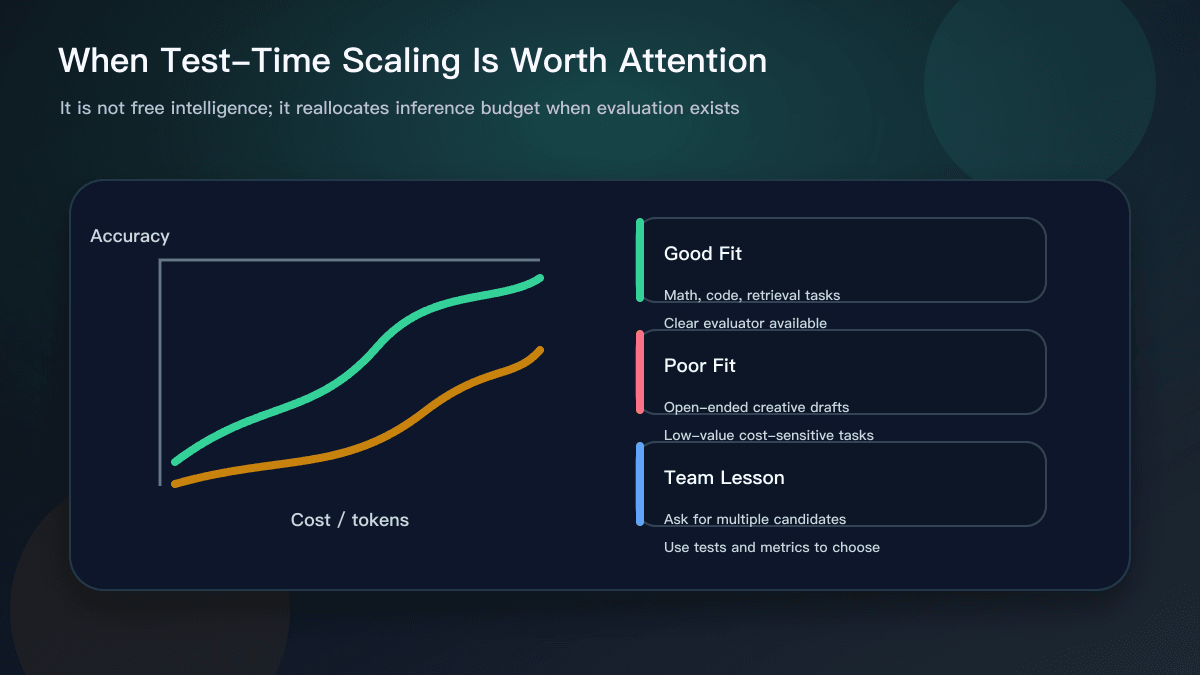
That is a different mindset from asking the assistant to get everything right in one shot. A more robust workflow is to ask the model for several candidate fixes, use tests and static checks to eliminate weak options, and then let a human review the surviving diff. For complex work, explore width first and then go deeper on one or two promising paths. For small work, cap the compute budget so the process does not spend too many tokens on a low-value task.
How Teams Can Use the Lesson Now
You do not need to implement AutoTTS to use the lesson. First, ask for two or three candidate approaches instead of one, and require each to name its verification method. Second, provide cheap feedback: test output, error logs, benchmark results, user examples, or review comments. Third, define stop conditions: pass these commands and stop, fail this many times and switch direction, exceed this time budget and return to human review.
Automation teams can apply the same pattern with Make. Split an AI workflow into candidate generation, field validation, retry rules, and human review. The point is not to make every step fully automatic. The point is to put each model call inside a feedback loop.
The paper is also a useful warning. More compute is not the same as free intelligence. More candidates and verifiers cost money and add latency. Test-time scaling is worth attention when the task is valuable, the evaluator is clear, and mistakes are expensive enough to justify the extra budget.
Why This Was Worth Covering
This research topic belongs in the daily-hotspot batch because it is recent, comes from arXiv, and translates into practical advice for AI coding agents and workflow evaluation. It is not a product launch, but it helps readers understand where tools may be going: not only stronger models, but agents that allocate reasoning budget more intelligently.
Sources:
- arXiv: LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling https://arxiv.org/abs/2605.08083
- AutoTTS repository mentioned in the paper abstract https://github.com/zhengkid/AutoTTS





