Google DeepMind 在 2026 年 5 月 7 日更新了 AlphaEvolve 的进展。它不是一个普通的代码补全工具,而是一个由 Gemini 驱动、面向算法设计和优化的编程代理。官方文章里最值得关注的,不是“又多了一个 AI coding agent”,而是它已经被用在基因测序、能源、电网、量子计算、TPU、数据库、物流、广告和材料科学等场景里。
这件事对 AI 工具用户有两个提醒。第一,AI 编程工具的价值正在从“帮我写代码”扩展到“帮我发现更好的算法”。第二,企业选择编程助手时,不能只看 IDE 体验,也要看它能否进入可评估、可回滚、可复验的优化流程。
AlphaEvolve 这次更新了什么
DeepMind 说,一年前他们介绍了 AlphaEvolve:一个用于设计高级算法的 Gemini 编程代理。现在这篇更新更像是一份应用清单,展示它已经在多个领域产生影响。
几个数字很直观:
- 在基因组学里,AlphaEvolve 帮助改进 DeepConsensus,让变异检测错误减少 30%。
- 在电网优化里,它用于 AC Optimal Power Flow 问题,让一个 GNN 模型找到可行解的比例从 14% 提高到超过 88%。
- 在地球科学里,它帮助优化 Earth AI 模型,让跨 20 类自然灾害风险预测的总体准确率提高 5%。
- 在量子计算里,它建议的量子线路相较传统优化基线错误降低 10 倍。
- 在 Google 基础设施里,它用于下一代 TPU 设计、缓存替换策略、Spanner 压缩启发式和编译器优化。其中 Spanner 场景把 write amplification 降低了 20%,编译器相关优化让软件存储占用减少接近 9%。
这些数字不能直接等同于普通团队明天就能复刻同样收益。它们更像是一个方向信号:当任务能被清楚定义、能自动评估、能反复试错时,AI 编程代理就不只是“生成代码”,而是在搜索更好的实现。

它和 Cursor、Copilot 不是同一类问题
如果你日常使用 Cursor 或 GitHub Copilot,AlphaEvolve 看起来可能离日常开发有点远。Cursor 解决的是项目上下文里的编辑、解释和跨文件修改。Copilot 解决的是低摩擦补全、测试样板和 IDE 内建议。AlphaEvolve 更接近“算法实验系统”:它要提出候选方案,再通过自动评估器筛掉不好的结果,留下真正能提升指标的实现。
所以不要把它理解成“Gemini 版 Copilot”。更准确的理解是:它展示了 AI 编程代理的高阶形态。当一个开发任务有明确目标函数,比如更低延迟、更少存储、更高准确率、更短路线、更低错误率,AI 就有机会在大量候选实现中搜索,而不是只给出一段看起来合理的代码。
这对普通团队也有启发。你不一定需要 AlphaEvolve 本身,但可以借鉴它背后的工作方式:把任务变成可验证问题。比如做性能优化时,不要只让 AI “帮我优化一下”,而是给出基准测试、约束、回滚方式和通过标准。这样 Cursor、Copilot、Gemini 或 Claude 才更可能产出可审查的改动。
企业最该学的是评估器
AlphaEvolve 能在这些场景里发挥作用,一个关键前提是有自动评估机制。算法候选不是靠聊天窗口里的解释取胜,而是靠指标取胜。能不能减少错误?能不能提高可行解比例?能不能降低写放大?能不能节省路线距离?这些问题都有可计算的反馈。
这也是很多团队用 AI 编程工具效果不稳定的原因:他们有生成器,却没有评估器。AI 能很快写出代码,但团队没有稳定的测试、benchmark、审查清单和生产指标,就很难知道这段代码到底是不是更好。
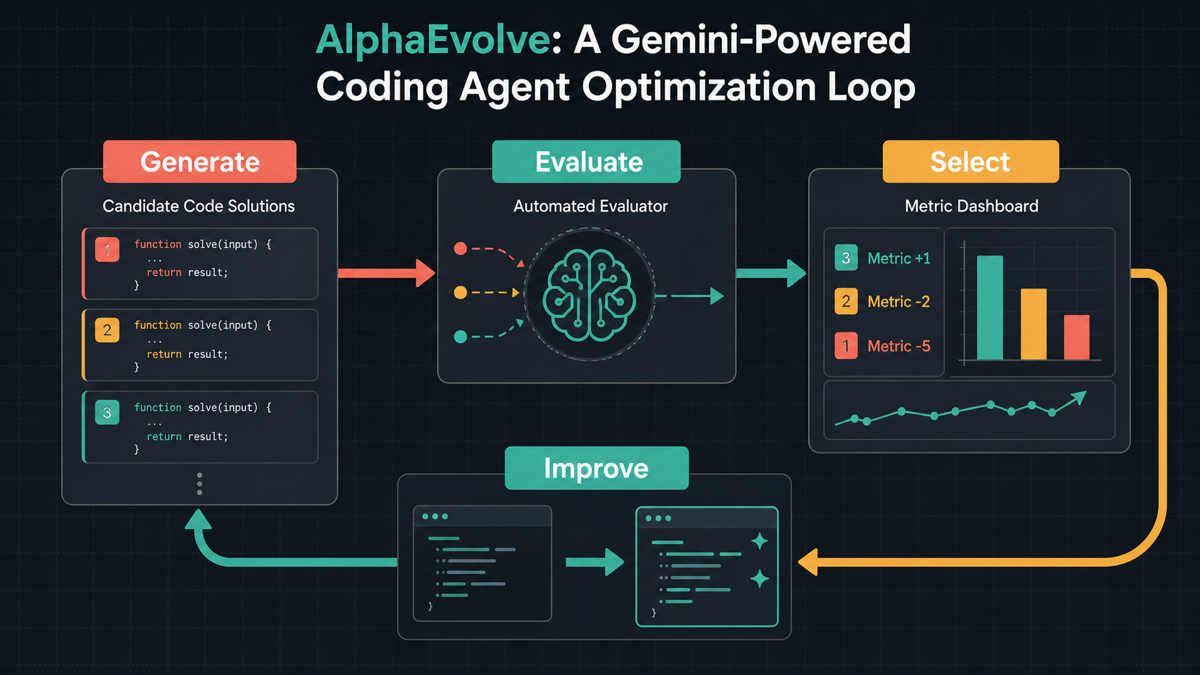
如果把 AlphaEvolve 的思路缩小到日常开发,可以落成四个动作:
- 先定义优化目标:速度、成本、准确率、可维护性,只能选少数几个。
- 再准备评估方式:单元测试、集成测试、性能基准或业务指标。
- 让 AI 生成多个候选方案,而不是只接受第一版。
- 用本地验证和人工审查筛选,保留可解释、可回滚的实现。
这样做会慢一点,但它能避免“AI 看起来很聪明,代码进仓后很难维护”的问题。
对 AI 编程工具选型的影响
这条新闻不会让 Cursor 或 Copilot 过时。相反,它让工具分工更清楚。
如果你要在仓库里改代码,Cursor 仍然更适合项目级编辑和多文件上下文。如果你要在熟悉 IDE 里快速补全代码,GitHub Copilot 仍然是低摩擦选择。如果你要围绕 Gemini 生态做算法、模型或 Google Cloud 相关实验,Gemini 和 DeepMind 这类能力会越来越值得关注。
真正的变化是评估标准。以后比较 AI 编程助手,不能只问“谁回答更像高级工程师”。更该问:
- 它能不能接住明确的评估指标?
- 它能不能生成多个候选方案?
- 它能不能解释为什么某个方案更好?
- 它能不能把改动限制在可审查范围内?
- 它能不能和测试、benchmark、CI、代码审查一起工作?
AlphaEvolve 的价值不是告诉每个团队马上换工具,而是提醒我们:AI 编程的下一阶段,重点不是更会聊天,而是更会在约束下优化。
可以怎么跟进
如果你只是个人开发者,可以先把这件事转化为一个小习惯:每次让 AI 改代码前,先写清楚验收命令。比如“改完必须通过 npm test 和 npm run build”,或者“性能不能比当前 benchmark 慢”。如果你是团队负责人,可以挑一个低风险、指标清楚的优化任务,让 AI 生成多个方案,再用测试和人工审查筛选。
AlphaEvolve 这次更新的重点,不是某个单点功能发布,而是一种工作范式正在变清楚:AI 负责提出候选,人类和评估器负责筛选,最终留下能被验证的改动。对 AI 编程工具用户来说,这比单纯追新模型更值得认真看。
参考来源:
- Google DeepMind:AlphaEvolve: How our Gemini-powered coding agent is scaling impact across fields https://deepmind.google/blog/alphaevolve-impact/





