2026 年 5 月 8 日,arXiv 上出现了一篇值得关注的论文:《LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling》。它提出 AutoTTS,把 test-time scaling 策略从人工设计的启发式,转成可以被代理自动发现的搜索问题。
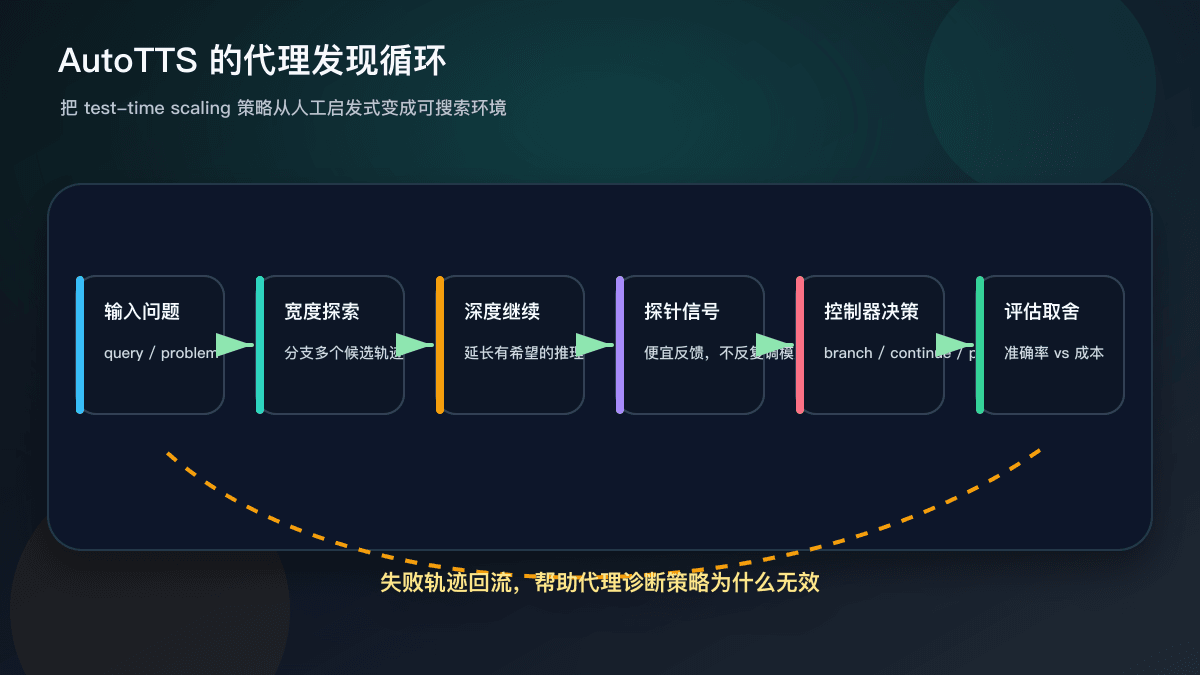
简单说,test-time scaling 是在推理阶段给模型分配更多计算,让它通过更多候选、更多步骤或更多验证来提高结果质量。问题是,很多策略过去靠研究者手写:什么时候多分支、什么时候继续想、什么时候停止、什么时候剪枝。AutoTTS 的思路是让代理在一个可评估环境里寻找这些控制策略。
这篇论文解决什么问题
论文摘要里有一个关键判断:现有 test-time scaling 策略很大程度上依赖人工设计,计算分配空间仍有很多没被探索。AutoTTS 改变了研究者要设计的东西:不是直接写每一种推理启发式,而是设计一个能让策略被自动发现的环境。
它的具体实例是 width-depth TTS。宽度对应多个候选轨迹,深度对应让某条推理继续走下去。控制器可以决定 branch、continue、probe、prune 或 stop。为了降低搜索成本,论文使用预先收集的推理轨迹和探针信号,让策略可以便宜地被评估,而不是每一次都重新调用大模型。
为什么 AI 工具用户也该关注
这看起来像纯研究,但它和日常工具使用很近。我们使用 Cursor、GitHub Copilot 或其他 AI 编程助手时,也在做一种 test-time scaling:让模型多给几个方案、让它写测试、让它解释失败原因、让它重跑验证、让它停止错误方向。差别只是我们通常靠人工提示词完成,而不是让代理系统化发现策略。
AutoTTS 的启发是:更强的 AI 工作流,不一定只来自更大的模型,也可能来自更好的预算分配。什么时候要多生成候选?什么时候要继续深挖一个方案?什么时候应该快速剪枝?什么时候该用便宜信号先判断方向?这些问题会直接影响成本和质量。
论文还报告说,发现出的策略在数学推理 benchmark 上改善了准确率和成本取舍,并能泛化到保留 benchmark 和模型尺度;整个发现过程成本为 39.9 美元、耗时 160 分钟。这个数字不能直接等同于你的业务场景,但它说明了一个趋势:推理策略本身也可以成为优化对象。
和 AI 编程有什么关系
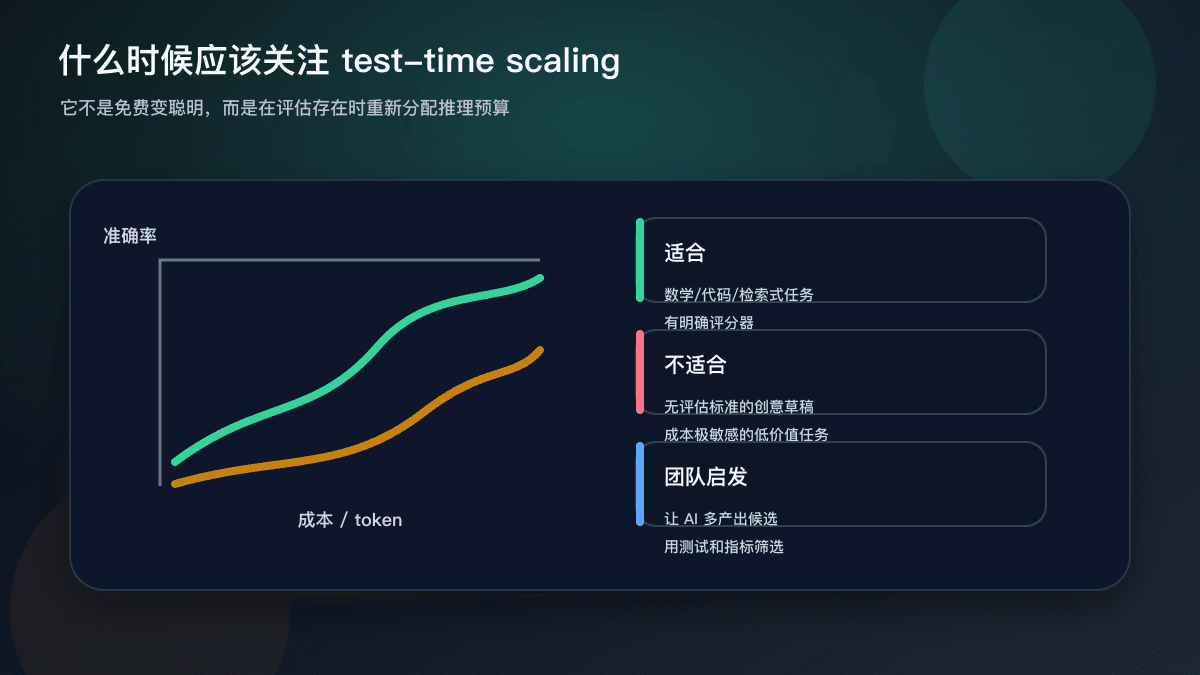
AI 编程任务特别适合借鉴这个思路,因为它通常有评估器。测试能不能过、类型能不能编译、性能有没有退化、lint 是否干净、diff 是否过大,这些都是反馈信号。只要反馈足够便宜、足够频繁,代理就可以在多个候选方案里做取舍。
这和“让 AI 一次写对”是不同思路。更稳的方式是让 AI 生成几个候选改法,用测试和静态检查筛掉不合格方案,再让人审查剩下的 diff。对于复杂任务,可以让代理先探索宽度,再选择一两个方向继续深挖。对于简单任务,反而应该限制计算预算,避免为了小问题消耗太多 token 和时间。
普通团队可以怎么用
你不需要实现 AutoTTS,也能把它变成工作习惯。第一,让 AI 不只给一个答案,而是给两个到三个候选方案,并说明每个方案的验证方式。第二,给它便宜反馈:测试输出、错误日志、benchmark、用户样例。第三,明确停止条件:通过哪些命令就停,连续失败几次就换方向,超过多少时间就退回人工判断。
如果你在做自动化流程,也可以用 Make 这类工具把 AI 步骤拆成“生成候选、验证字段、失败重试、人工复核”。这里的核心不是追求全自动,而是把每一次 AI 调用都放进一个有反馈的流程里。
这篇论文还提醒我们,不要把“更多计算”误解为“免费变聪明”。增加候选和验证会提高成本,也可能带来延迟。只有当任务价值足够高、评估器足够明确、错误成本足够大时,test-time scaling 才值得认真使用。
选题判断
这篇研究适合进入每日热点,因为它来自 arXiv 前沿论文,发布时间新,主题又能转化成 AI 编程代理和工作流评估建议。它不是普通产品新闻,但能帮助读者理解未来 AI 工具可能怎么变:不只是模型更强,而是代理更会分配推理预算。
参考来源:
- arXiv:LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling https://arxiv.org/abs/2605.08083
- AutoTTS 代码仓库(论文摘要声明将开源) https://github.com/zhengkid/AutoTTS





