OpenAI 在 2026 年 5 月 8 日发布了《Running Codex safely at OpenAI》。这篇文章不是一个普通的功能更新,而是一份面向工程团队的运行手册:当 AI 编程代理可以读项目、改文件、跑命令、调用工具时,团队真正要设计的不是“让它更会写代码”,而是让它在可控边界里工作。
官方提到的关键词很集中:沙箱、审批、网络策略、配置管理、详细的代理感知遥测,以及用 Codex 日志做安全分诊。对站内用户来说,这条新闻值得看,不是因为每个团队都能复制 OpenAI 的内部规模,而是因为它把 AI coding agent 的采用标准说清楚了:代码生成能力只是入口,能否被限制、观察、复盘和回滚,才决定它能不能进入团队流程。
这次更新真正说明了什么
很多人评估 Cursor、GitHub Copilot 或 ChatGPT 编程能力时,会先看它们能不能一次写对代码。这个角度不算错,但不够。OpenAI 这次强调的是运行控制面:代理在哪个环境执行、什么操作需要人批准、网络访问如何限制、工具调用和失败结果如何留下证据。
这意味着团队采用 AI 编程代理时,不能只给一个“请修复这个 bug”的任务。更好的任务应该包含仓库范围、禁止改动区域、验收命令、网络规则和人工审批点。AI 可以在低风险区域里多试几种方案,但涉及生产配置、依赖安装、凭据、支付、权限和数据迁移时,要有明确的拦截点。
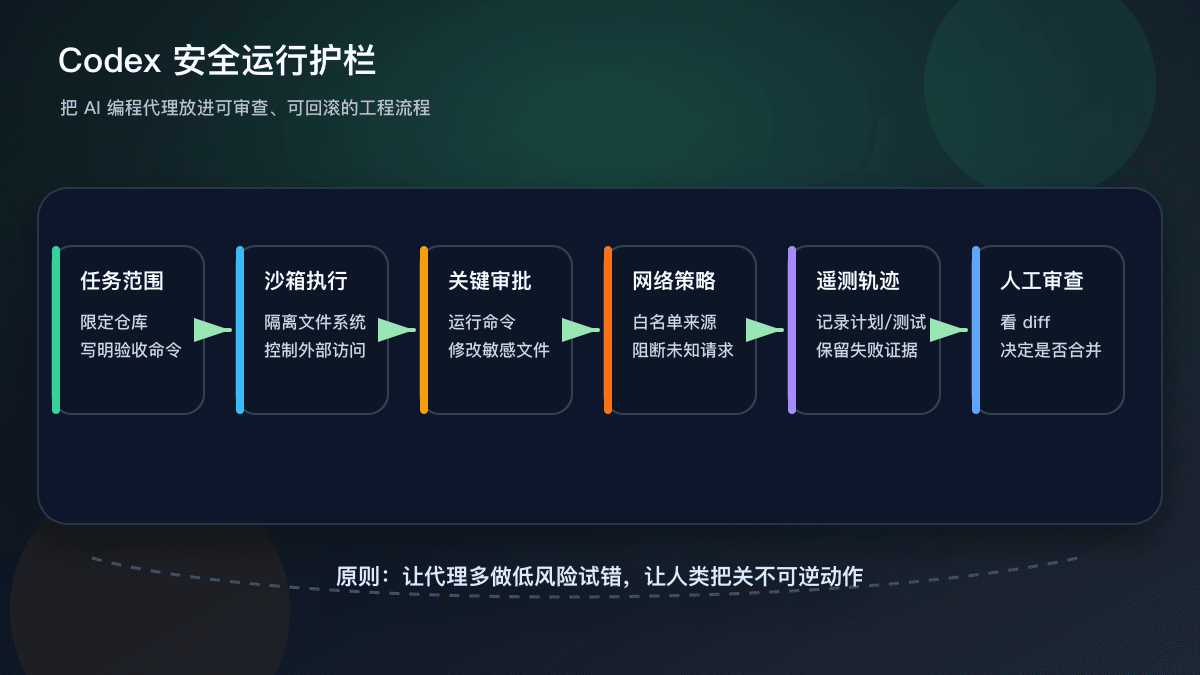
对普通开发团队有什么价值
这篇文章最实用的地方,是它把“安全使用 AI 编程代理”从抽象口号变成了几个工程动作。第一,沙箱不是摆设,它让代理的试错和真实环境隔开。第二,审批不是降低效率,而是把不可逆操作交还给人。第三,网络策略能减少代理在未知来源之间自由穿梭。第四,遥测不是事后甩锅,而是让团队知道一次任务里发生过哪些工具调用、命令结果和策略拦截。
如果你现在只是个人开发者,也可以把这套思想缩小到本地流程里。比如让 AI 改代码前先说清楚“只能改这几个文件”;让它运行命令前先说明目的;每次完成后必须给出测试输出;合并前人工看 diff。你不需要一开始就搭建复杂平台,但可以先让代理的每一步有记录。
如果你是小团队负责人,建议从低风险任务开始:文档补全、测试补齐、类型修复、重复代码清理、旧页面样式调整。先观察 AI 在这些任务上的失败模式,再决定是否扩大到核心业务逻辑。不要一开始就把代理放进支付、权限或数据删除链路里。
和 Cursor、Copilot 的关系
这条新闻不会让 Cursor 或 Copilot 失去价值,反而会让它们的分工更清楚。Cursor 更适合项目级上下文和跨文件编辑,Copilot 更适合 IDE 内补全和低摩擦建议,ChatGPT 适合解释、拆解任务和生成检查清单。Codex 的这篇运行经验提醒我们:不管用哪一个工具,团队都需要一层“代理运行制度”。
评估工具时,可以多问几个问题:它能不能限制文件范围?它能不能在执行命令前说明意图?它能不能把测试、失败和回滚建议说清楚?它能不能配合现有分支、代码审查和本地验证?如果一个工具很会生成代码,但生成过程不可见、边界不可控,团队采用成本会被隐藏到后续维护里。

可以怎么跟进
一个可执行的跟进方式,是给团队写一份“AI 编程代理任务模板”。模板里至少包含五项:目标、允许修改的文件、禁止修改的文件、验收命令、需要人工批准的动作。之后每次让 AI 处理任务,都按这个模板发起,而不是靠聊天里的临时提醒。
第二个动作是把失败也纳入流程。不要只保存成功 diff,也要记录代理运行过哪些命令、哪里失败、为什么回滚。OpenAI 提到的代理感知遥测,本质上是在提醒团队:AI 代理不是普通脚本,它的决策路径也要可观察。没有这些记录,出了问题很难判断是需求写错、工具误用,还是审批规则太松。
第三个动作是把本地验证前置。比如要求每个 AI 改动都必须提供 npm test、npm run build 或对应语言的验证命令。代理可以建议命令,但人要确认它真的跑过、失败怎么处理、是否覆盖原始需求。对工程团队来说,这比“回答看起来像高级工程师”更可靠。
选题判断
这篇属于值得写的热点:它来自 OpenAI 官方,主题和 AI 编程工具强相关,而且能转化成站内用户的工具选型和团队流程建议。相比“某个模型又更新了一个小功能”,它更接近长期可复用的工作方法。
参考来源:
- OpenAI:Running Codex safely at OpenAI https://openai.com/index/running-codex-safely/
- OpenAI Security 新闻页 https://openai.com/news/security/





