Artificial Analysis 在 2026 年 5 月 11 日的 changelog 里上线了 Artificial Analysis Coding Agent Benchmarks。这件事之所以值得站内用户认真看,不是因为“又多了一个排行榜”,而是因为它终于把团队挑编程代理时最容易分裂的几个维度放到了同一页:效果、耗时、成本、token 消耗,以及同一个底层模型在不同代理壳里的表现差异。
如果你过去看 AI 编程工具,常常会遇到一个问题:大家拿着不同 benchmark、不同设置、不同模型和不同界面在比,最后讨论半天,还是不知道该选 Claude、Cursor 还是别的 coding agent 入口。Artificial Analysis 这次做得最有价值的地方,是它没有只给一个“谁第一”的结论,而是把比较逻辑拆开了。
这次上线的页面到底提供了什么
Artificial Analysis 公开页给出的结构很清晰:
- 一个
Artificial Analysis Coding Agent Index - 三个组成 benchmark:
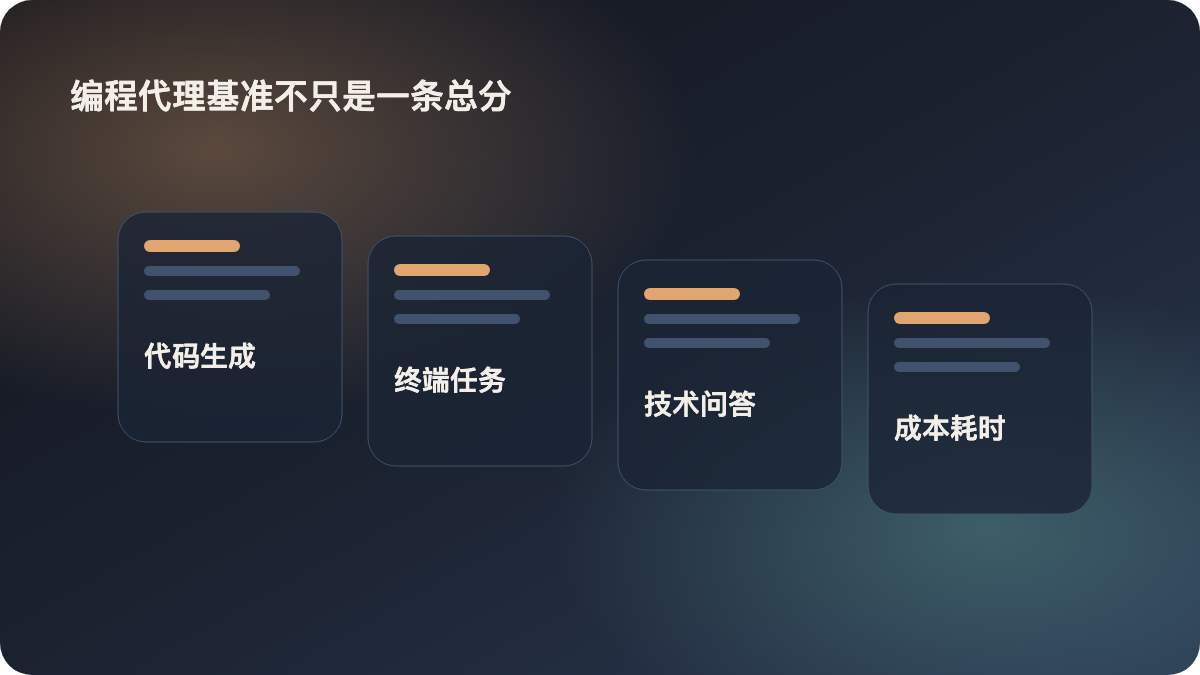
SWE-Bench-Pro-Hard-AA,150 个代码生成问题Terminal-Bench v2,84 个 agentic terminal use 问题SWE-Atlas-QnA,124 个技术问答问题
- 指数计算方式是这 3 个 benchmark 在 3 次运行下的
pass@1平均值 - 除了总指数,还同时展示 cost、token usage 和 execution time
- 页面还提供 methodology,解释指标怎么聚合、什么叫 solved、为什么不能只看 headline score
这意味着它不是单纯在回答“谁最强”,而是在回答“谁在什么代价下、以什么节奏、用什么代理壳,完成了哪类任务”。这比只晒一个单点分数更接近团队的真实选型问题。
为什么这比普通 leaderboard 更有用
很多团队做工具选型时,最大的误区不是没看 benchmark,而是看得太单一。比如只看代码 patch 成功率,就会忽略终端任务和仓库问答能力;只看模型名,就会忽略同一个模型在不同 harness 下的巨大差异;只看效果,就会忽略有些代理虽然分数高,但单任务耗时和成本也明显更高。
Artificial Analysis 这页最实用的点,是它同时把这些维度放出来,逼你换一种比较方式:
- 如果你更在意仓库理解,就不能只看 patch 类题目。
- 如果你更在意长回路 CLI 任务,就必须看 terminal workflow。
- 如果你更在意真实团队落地,就不能只看结果,还要看单任务时间和成本。
- 如果你想比较产品而不是模型,就要看同模型不同代理壳的 harness comparison。
这恰好对站内用户非常重要。因为本站很多读者并不是“研究哪个模型最强”,而是“我应该把团队的 AI 编程入口放到哪里”。这是两个完全不同的问题。
它最值得学的不是总榜,而是比较框架
Artificial Analysis 明确写到,Coding Agent Index 是一个 composite score,而且应该和单项 benchmark 一起读。这个提醒很关键,因为现实里两类代理很可能总分接近,但强项完全不同:
- 有的更擅长仓库理解和技术问答
- 有的更擅长直接改代码和过 evaluator
- 有的更擅长终端执行和多步命令工作流
页面还专门提供了 harness comparison,把同一个底层模型固定下来,再看不同 coding-agent harness 的差异。这一点对团队特别有帮助,因为很多时候你以为自己在“比模型”,其实真正影响体验的是代理壳、上下文组织、命令策略和工具调用方式。

这也解释了为什么这篇文章的 relatedTools 精确挂在 claude、cursor 和 github-copilot。读者想解决的不是“基准网站哪个好看”,而是“我现在该怎么更稳地比较这几类 AI 编程入口”。
对普通团队最实际的启发
如果你是个人开发者,这页最适合拿来做的,不是盲目追榜,而是重新校准自己的任务类型。先问自己,你最常做的是哪类工作:
- 仓库问答和代码阅读
- 小到中等范围的 patch 和修复
- 终端驱动的长回路工作流
如果你是团队负责人,更适合把这页变成一套内部评估模板,而不是直接当采购结论。一个更稳的做法是:
- 先把团队工作切成 3 类任务:仓库理解、改动交付、终端长任务。
- 对照 Artificial Analysis 的 3 个 benchmark,看它们分别更接近哪类内部工作。
- 再把候选工具按效果、耗时和成本做一次本地小样本试跑。
- 最后再决定是继续深用现有入口,还是新增第二套长任务代理栈。
这样做会比“看一眼总榜然后换工具”稳得多。
为什么今天值得发,但不该被误读成唯一答案
这条热点值得今天发,是因为它具备很强的时效性和搜索意图:2026 年 5 月 11 日刚上线,而且直接服务 AI 编程工具选型。它不是泛泛的媒体报道,而是一个高信噪比、可追溯的方法型入口。
但它也不该被误读成“总榜第一就等于你该选它”。Artificial Analysis 自己在 methodology 里已经提醒,复合指标需要结合单项 benchmark、成本、token 和执行时间一起看。对真实团队来说,最重要的不是谁赢了,而是你准备把哪类工作交给谁。
参考来源:
- Artificial Analysis: Coding Agent Benchmarks
- Artificial Analysis: Coding Agent Index Methodology
- Artificial Analysis: Changelog